


Anthropic: The Volvo Strategy
Why the safest AI company might win the AI race


On a crisp morning in Washington, D.C., a new AI model quietly earned what amounts to a government "top-secret" badge. Anthropic's Claude had just been cleared for FedRAMP High and DoD IL4/5, meaning it can handle some of the U.S. government's most sensitive unclassified data. In an AI industry obsessed with speed and horsepower, Claude's security clearance was like a Volvo winning praise at a supercar show, not for being the fastest, but for being the safest.
This unexpected badge of safety is our starting gun. The race to deploy AI is entering a new phase where safety features could decide the winners.
The Foundation, Not the Wrapper
Meet Claude: Anthropic's entry in the frontier AI model race. But here's what matters: Claude isn't just another ChatGPT wrapper with a prettier interface. It's a foundation model, built and trained from scratch by Anthropic. Think of it as owning the engine, not just the car.
Many so-called AI products are wrappers, nice interfaces that secretly call OpenAI's API under the hood. Anthropic instead offers the model itself. Companies get direct access to Claude's capabilities, can integrate it into their own applications, or even fine-tune variants. It's the difference between renting a car and owning the manufacturing plant.
Claude operates with what's called a massive context window—200,000 tokens, or roughly 150 pages of text that it can consider simultaneously (By comparison, OpenAI’s GPT-4 tops out around 128,000 tokens in its expanded version, about 24 pages of text). While GPT-4 handles about 24 pages, Claude can ingest entire financial reports, legal briefs, or codebases in one shot. It's like having a photographic memory that can hold a novel-length document while reasoning across every page.
The technical architecture matters because it enables something unique: visible reasoning. In Claude 3.7, Anthropic introduced Extended Thinking Mode—essentially a "show your work" feature where you can watch Claude's chain of thought unfold in real-time. It's transparency that most AI models keep hidden, like being able to see the gears turning in a Swiss watch.
This isn't just a technical novelty. For enterprises dealing with sensitive data, having an AI that can explain its reasoning process—and keeping that reasoning transparent—is the difference between a tool you can trust and one you can't deploy at scale.
The Exodus and the Mission
In late 2020, Dario Amodei and a cadre of top researchers left OpenAI after growing uncomfortable with the company's direction. OpenAI had pivoted from a non-profit lab into a for-profit entity, and the departing team, including Dario's sister Daniela Amodei, believed there was a better way: a new AI lab founded on a "safety-first" ethos.

Why strike out on their own? As Dario later explained, the group at OpenAI had become convinced of two things: that pouring more compute into models would keep making them smarter, and that you also needed to explicitly align those models with human values as they scaled. “You don’t tell the models what their values are just by pouring more compute into them,” he said, so the team that cared deeply about safety went off and started our own company with that idea in mind.
But the Amodeis didn’t just start another tech startup. They architected something unprecedented: an AI company with governance as a moat. Anthropic was incorporated as a Public Benefit Corporation (PBC), with a mission legally embedded in its charter. In practice, this means Anthropic’s board has a fiduciary duty not only to maximize shareholder value, but also to ensure that “transformative AI helps people and society flourish,” even if that means sacrificing profit.
To bolster this mandate, the founders set up a Long-Term Benefit Trust (LTBT) – an independent body of experts in AI safety, national security, and public interest (none of whom hold equity).

The Trust is empowered to elect and fire a portion of the board of directors. As Anthropic hits certain funding and milestone triggers, the Trust’s power grows: by late 2025, it will elect 3 of 5 board members, a majority. Dario Amodei has argued that this structure aligns the interests of the public, employees, and shareholders in a way that gives Anthropic leeway to put safety first.
In other words, Anthropic can credibly tell customers and regulators: “We’re not going to cut safety corners, because our very DNA forbids it.” Unlike a traditional corporation, shareholders can’t sue simply because the board hits pause for safety reasons (Whether the public could ever sue the board for not prioritizing safety is an open question).
Seat-Belt Engineering
Anthropic isn’t just building AI models; it’s engineering the seat belts and airbags for them. The company’s Responsible Scaling Policy (RSP) is essentially a safety manual for riding the edge of AI capability.

The one-liner: as Anthropic’s models get more powerful, they won’t simply “move fast and break things.” Instead, they’ve publicly committed to throttle their own progress if needed.
The RSP lays out AI Safety Levels (ASL) – think of biohazard containment levels, but for AI.
Under the RSP, if a model shows “any meaningful catastrophic misuse risk under adversarial testing by world-class red-teamers,” Anthropic will not deploy it. They’d first require proven fixes or security measures before proceeding. Crucially, the governance apparatus enforces this promise. The Board of Directors formally approved the policy, and any changes must be approved by the Board and the Trust. Anthropic even appointed a Responsible Scaling Officer to audit compliance every quarter. It’s the kind of safety bureaucracy built into the company’s DNA that you’d expect in aerospace or biotech, not in a Silicon Valley AI lab.
Critics point out this is still voluntary self-policing – a pledge, not law. Indeed, all major AI labs are under pressure to compete, and a policy is only as good as the will to enforce it. Will Anthropic actually slam the brakes when profits and rivalry heat up? That remains to be seen. But Anthropic counters that, as a PBC with an oversight trust, it’s uniquely structured to uphold its safety vows. The RSP is a live test of voluntary governance: Dario hopes it can spark a “race to the top” on safety, pressuring others to make similar commitments. (Notably, by 2024 both OpenAI and Google DeepMind had indeed published their own versions of scaling/safety policies).
However, such frameworks could easily fall by the wayside to the profit motive and ultimately will need government regulation to truly hold companies accountable. For now, Anthropic bets that binding itself to the mast of safety is both principled and, in the long run, practical.
Who Pays for Safety
Claude’s safety-first design isn’t just moral positioning, it’s a market strategy. Anthropic is deliberately targeting customers who need the seat-belts: heavily regulated industries and government agencies where a model that’s less likely to go rogue isn’t a nice-to-have, it’s a must-have. In other words, safety sells – if you sell it to the right market.
The early enterprise adopters tell the story. Brex, a fintech unicorn, chose Claude via AWS’s Bedrock platform after evaluating multiple AI models. Why Claude? Brex’s AI lead David Horn cited Anthropic’s approach to data privacy and security as the deciding factor. “When I talk with customers about AI, data privacy is always their first concern – it’s the critical foundation we have to address before we can even begin discussing capabilities,” Horn noted.
Anthropic’s newly minted FedRAMP High authorization opens even bigger doors. U.S. federal agencies have over $3.3 billion allocated for AI R&D in FY2025, not counting operational spending, and many defense and civilian agencies quite literally cannot use tech that isn’t FedRAMP certified. Now, Claude is one of the few frontier models cleared for deployment across the federal landscape, enabling secure AI chatbots, document analysis, and intelligence support in settings that demand stringent compliance. In the Pentagon’s world, this is a rare AI that checks the security boxes. As Anthropic’s announcement put it, Claude can now serve “the full spectrum of unclassified government workloads” on secure cloud regions – unlocking multi-million-dollar contracts that would have been off-limits before.

The revenue trajectory so far validates the strategy. By May 2025, Anthropic hit approximately $3 billion in annualized revenue run-rate – a leap from roughly $1 billion in December 2024. While OpenAI grabbed headlines courting consumers with ChatGPT, Anthropic quietly built an enterprise rocket ship selling AI-as-a-service to businesses.

The financial numbers also reveal the audacity of Anthropic’s approach. The company reportedly burned $5.6 billion in 2024, outpacing its revenue by roughly 5x. Yet they’ve raised massive capital to sustain this cash burn.
A $3.5 billion Series E in early 2025 valued Anthropic at around $61.5 billion. And Amazon’s strategic partnership came with up to $4 billion more investment (announced in late 2024) for a minority stake. It’s a high-stakes bet: that hyper-growth in adoption will intersect with declining unit costs, flipping the economics to breakeven by around 2027. Indeed, Anthropic has told investors it projects revenue as high as $34.5 billion by 2027 in a bullish scenario, which would certainly justify the current spending. The company is essentially sprinting for scale, confident that being first to lock down enterprise and government clients with a trustable AI will yield a winner-take-most position.
The Speed vs. Safety Matrix
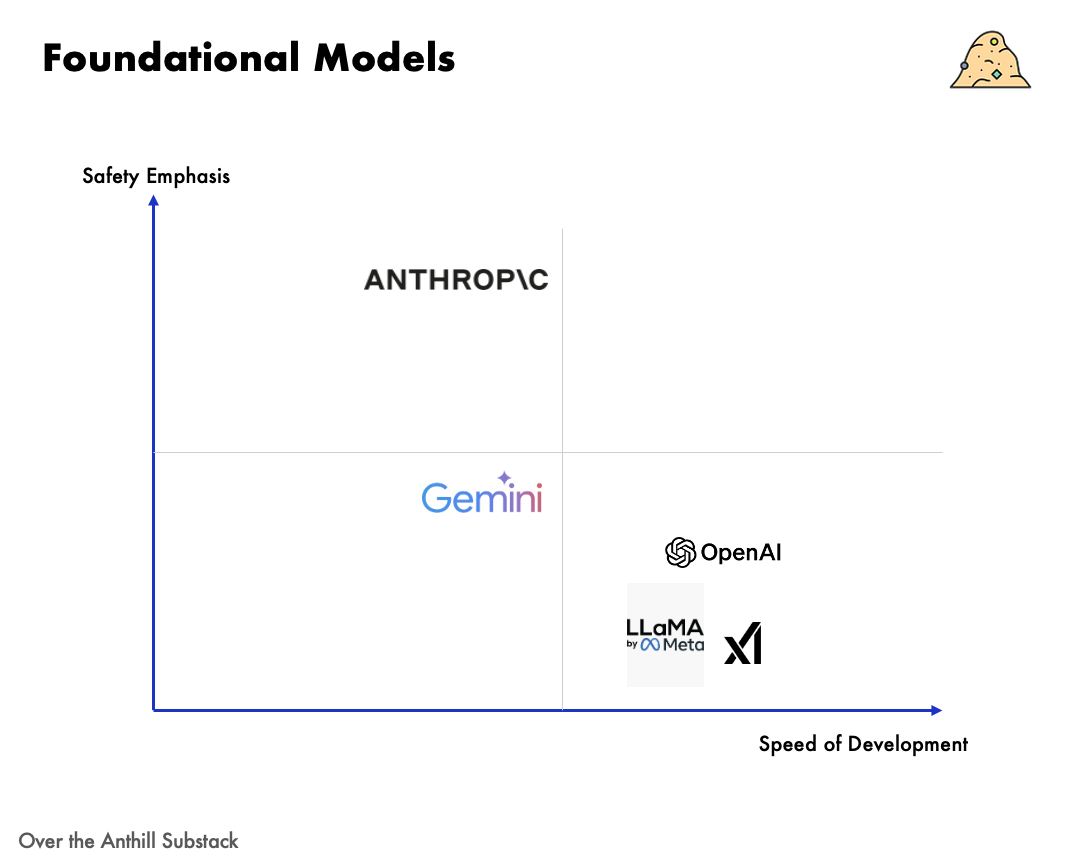
To understand where Anthropic stands, imagine a 2×2 matrix. One axis measures speed of AI development—how aggressively companies push out new models. The other measures safety emphasis—how much caution and governance they bake in.
Anthropic occupies the "Safety-First Tortoise" quadrant. They roll out models more cautiously, spend heavily on alignment research, and will delay launches for safety. The bet: enterprise customers and regulators will favor the tortoise who built safer products, even if it meant being slower to market.
OpenAI sits in "Move Fast and Fix Later." They iterate rapidly, witness the quick succession of GPT-4, GPT-4 Turbo, and other updates, and have taken public flak when things go wrong. OpenAI certainly invests in safety, but critics say they at times prioritize launches ahead of comprehensive risk analysis, evidenced by post-release fixes and policy flip-flops. In fact, in April 2025, OpenAI signaled it might loosen its safety standards if rivals released risky AI models without similar safeguards. The company even launched its GPT-4.1 model without the usual public safety or system card, prompting one former OpenAI safety researcher to lament that “OpenAI is quietly reducing its safety commitments.”

It’s exactly the kind of dynamic Anthropic hopes to avoid, or capitalize on, by being the steadier hand.
The open-source community and emerging players like xAI occupy "Cowboys & Open Source." They release models with minimal restrictions, aiming for speed and openness. Meta's LLaMA releases exemplify this—open-sourced relatively quickly with basic safety tuning. The advantage is rapid innovation; the risk is obvious incidents with no centralized authority to intervene. (Meta faced controversy when LLaMA’s weights leaked and people fine-tuned it for questionable purposes.)
Google historically occupied "Cautious Laggards"—slow to deploy advanced models due to reputational concerns, yet without differentiating safety solutions. It's a losing position: neither leading on tech nor trust. Google is now moving toward the middle, trying to balance speed with safety.
In theory, every AI lab wants to be in the “High Speed & High Safety” quadrant, moving fast and not breaking things, but in practice that’s more ideal than reality. Everyone faces trade-offs. More safety diligence and red-teaming will slow you down; racing ahead means accepting more unknown risks. Anthropic has explicitly chosen safety over speed as its north star, hoping to carve out a durable niche even if they’re not first with the flashiest features. In an industry where the winners often reap outsized rewards, it’s a bold play to be the tortoise. But then again, if the “fast movers” trip on a regulatory ban or a public backlash, the tortoise might find itself steadily cruising past the hare.
The Risk Ledger
No strategy is risk-free. Anthropic’s careful positioning comes with at least three major vulnerabilities that could undermine its long-term edge:
The Pause Button Dilemma. Anthropic's credibility rests on actually hitting the brakes when their RSP demands it. But what happens when GPT-5 launches and OpenAI grabs massive market share while Anthropic sits in safety review? The pressure to quietly loosen their own standards could become enormous. We’ve already seen a crack in the facade: in May 2025 Anthropic released Claude Opus 4, a model it classified as ASL-3 (high-risk), without publicly defining an ASL-4 standard beforehandm, even though the original RSP promised not to release an ASL-3 model until ASL-4 was defined. Essentially, they said “trust us, we’ve done enough safety” and ruled that Claude Opus 4 didn’t warrant invoking a next-level halt. When pressed by journalists, Anthropic argued that it had revised the RSP in late 2024 and that ASL-4 would now be defined differently. Perhaps that’s reasonable. But if, in the crunch of competition, Anthropic were to abandon its cherished principles entirely, its unique selling point would evaporate overnight. The real test will be the first time self-restraint carries a multi-billion-dollar price tag in market share.
Amazon Dependency. Amazon isn't just a partner, it's a major investor with board observation rights. Claude's primary deployments run on AWS Bedrock, creating concentration risk. If AWS experiences outages or Amazon decides to promote competing models, Anthropic could lose its primary sales channel. So far, the relationship is symbiotic: Amazon needs a strong AI partner to compete with Microsoft/OpenAI, and Anthropic needs AWS’s scale. But tech history is littered with platform-vendor romances that soured when interests diverged. Anthropic is betting that aligning with Amazon gives it distribution and funding without giving up independence, essentially, riding on a friendly elephant. It will have to tread carefully that the elephant never decides to step on it.
3. Imitation Erosion. What if Anthropic’s safety focus becomes less differentiating over time – basically table stakes for everyone? OpenAI, Google, and others are visibly ramping up their alignment and safety work. By 2026, it’s conceivable that every serious AI provider will tout “Constitutional AI” style training, publish their versions of RSPs, and comply with whatever new AI regulations emerge. In fact, Anthropic’s voluntary policy push has already spurred similar moves by its rivals. Governments are also likely to mandate certain safety standards. In that world, Anthropic’s unique selling point could fade. If all players meet roughly the same safety baseline, buyers might just choose based on raw performance, features, or price, arenas where bigger competitors (with more data and cash) could have the upper hand. Anthropic is hoping its head start in safe AI and its credibility will continue to set it apart. But the window for “safety as differentiator” could narrow if the rest of the industry catches up or if regulations level the playing field.
Future Bets and the Road Ahead
Looking forward, Anthropic isn't just planning to "make better Claude and sell more of it." They're angling to reshape the AI services landscape with three major opportunity areas.
Alignment-as-a-Service could package Anthropic's safety tools and expertise for other organizations. As AI regulations tighten—55% of organizations say they're unprepared for AI compliance—there's a market for licensing safety tech. Anthropic might one day help even competitors align their models, turning deep research into revenue streams independent of Claude usage.
Vertical Claude models represent the move toward domain-specific AI. Instead of one-size-fits-all, Anthropic could create versions tailored to legal analysis, biotech research, or customer service, each with industry-specific knowledge and compliance baked in. A "Claude Finance" that inherently follows FINRA guidelines, or "Claude Health" that knows HIPAA rules. The market for vertical AI is expected to reach ~$47 billion by 2030.
Compliance Arbitrage turns regulatory complexity into a competitive advantage. As governments impose stricter AI rules, many providers will scramble to adapt. Anthropic, by design, is ahead on compliance—their visible reasoning, robust documentation, PBC status, and Trust structure curry favor with regulators. Every new rule becomes not a hurdle but a ramp they're already driving on.
These bets align with making money while extending "safety" from feature to full product suite. If even one pays off, Anthropic could unlock revenue streams beyond API calls, crucial for hitting their ambitious projection of $34 billion in revenue by 2027.
These bets all align with turning “safety” from just a product feature into a full-blown product suite and brand moat. They also diversify where the company’s revenue could come from – important if Anthropic is to hit its aggressive targets by 2027. Even if one of these bets pays off moderately, it could open up new lines of business beyond selling API access to Claude. And if all three pay off, Anthropic could evolve from an AI model provider into something more like an AI solutions platform, dominating the high-trust end of the market.
Claude’s Pentagon-grade clearance and the company’s swelling revenues show that, at least in enterprise markets, safety sells and trust can be monetized. The ultimate test, however, will come when competitive pressure ratchets up. Will Anthropic truly slam the brakes to keep things safe, or will it find a clever detour that lets it maintain both safety and speed?
The automotive analogy holds. Volvo didn't win every street race, but their safety innovations eventually became industry standard. Seatbelts, airbags, crumple zones, all Volvo inventions that every manufacturer now includes. Anthropic is betting the same dynamic will play out in AI: that their safety-first approach will set benchmarks others follow.
The question isn't whether Claude will be the fastest AI, it's whether being the safest, most trustworthy AI proves to be the better long-term strategy. In an industry where one catastrophic failure could trigger sector-wide regulation, Anthropic's Volvo approach might not just be noble, it might be the smartest business strategy of all.
Time will tell if their approach puts them ahead of the pack, or merely on higher ground as others rush by. But in a world increasingly wary of unchecked AI power, there's something to be said for being the company that builds the seatbelts first.